Core Image【4】—— 2018 新特性

Core Image 系列,目前的文章如下:
如果想了解 Core Image 相关,建议按序阅读,前后有依赖。
概述
2018,Core Image 主要更新了三个点:性能优化,原型开发,以及与 CoreML 的结合。
整体更新的不多,但都比较有意思。下面逐一详细阐述。
Performance
性能方面,2018 主要更新了两点:
- intermediate buffers,中间缓存
- new CIKernel Language features,CIKernel 新特性,按组读写
intermediate buffers
首先,回顾下 Core Image 滤镜链现有的工作方式:
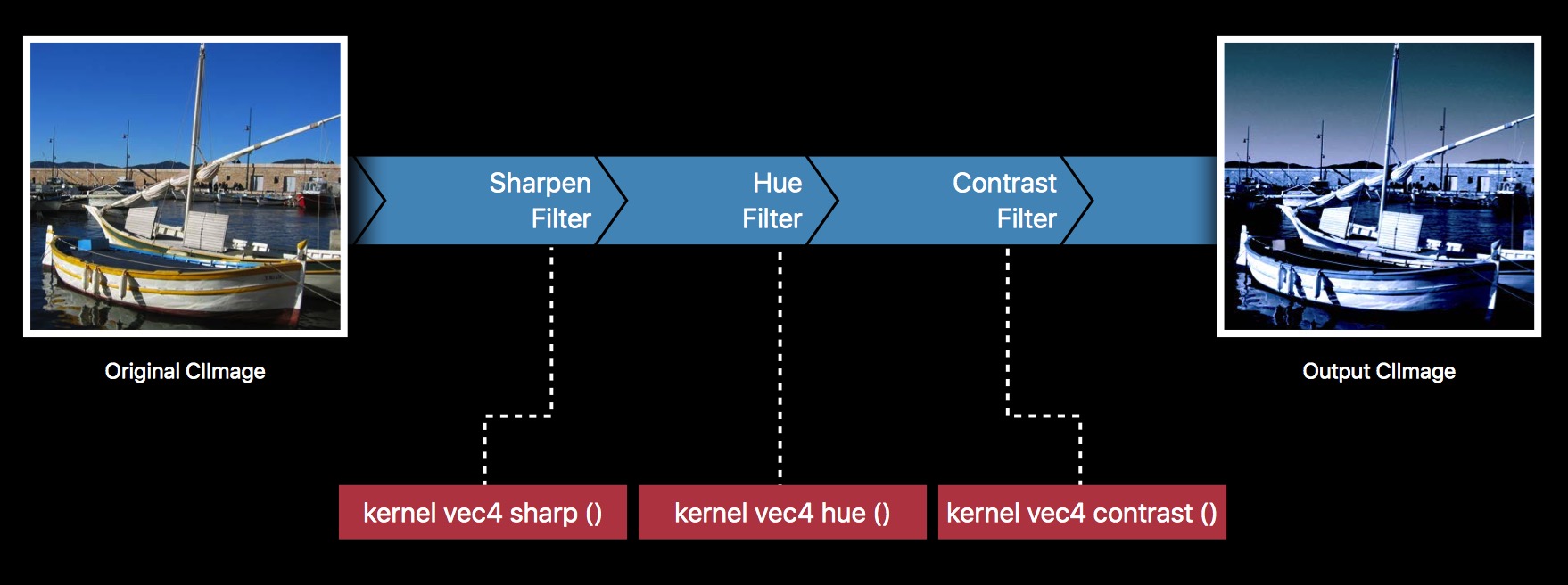
我们可以通过这样首尾相连的方式,组合不同的 Filter,达到我们想要的效果,各个 Filter 又对应着各自的 Kernel,我们也可以自定义 Kernel。
PS:
关于如何使用滤镜链,以及如何自定义 Filter,如果有不了解的,可以翻看前两篇文章。
这里不再阐述。
Core Image 为了性能,包括处理速度,以及降低内存,会自动把整个滤镜链,优化成一个 Filter 处理,如下:
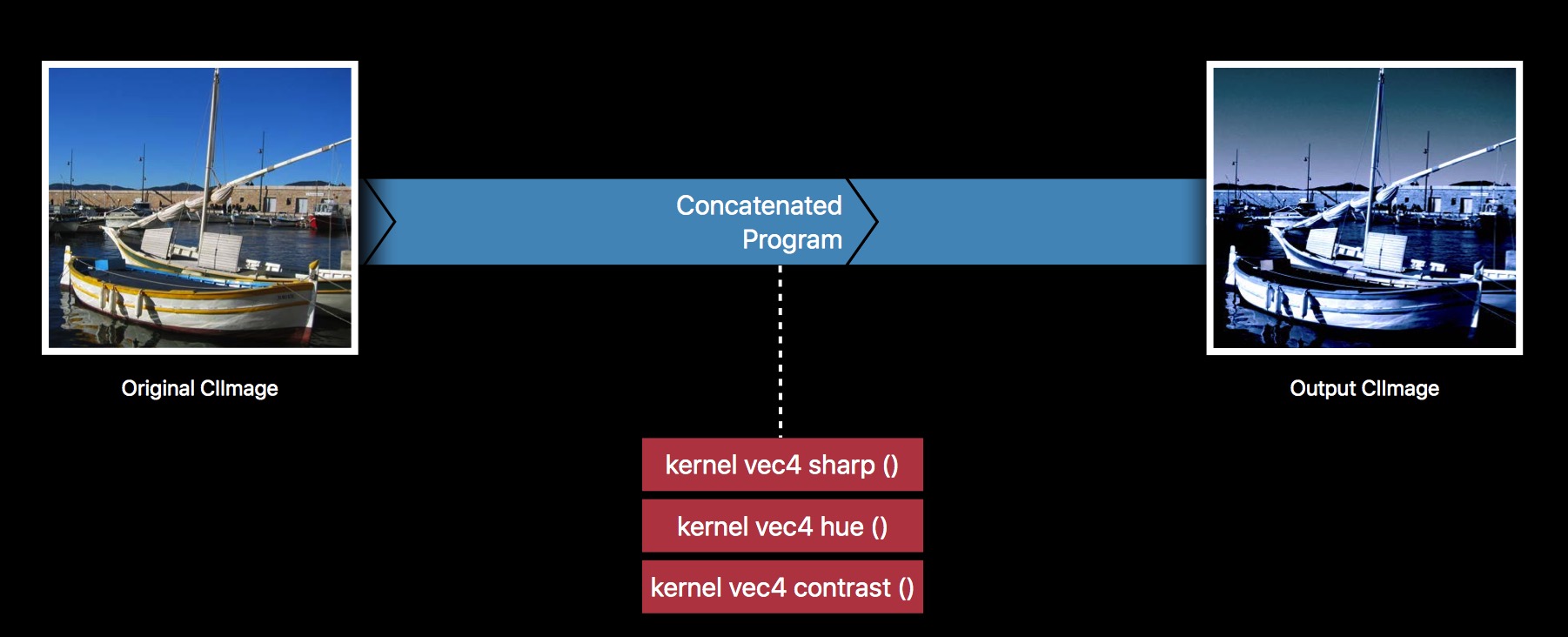
这可以说是 Core Image 很厉害的地方,也正因为这个特性,Core Image 在处理滤镜链上,性能比 GPUImage 要好得多。
PS:
GPUImage 的做法,和我们平时的处理方式一致,是按序处理的,没有优化,即 原图— Filter1 —> 结果图1 — Filter2 —> 结果图2 —> Filter3 —> 结果图 这样的一个过程。这期间产生了两个中间缓存,即 结果图1 和 结果图2。
当然,Core Image 减少中间缓存,提高性能,绝大多数情况下,都是非常棒的,但也有一些情况下,需要额外去修改,扩展。
比如这样一个场景:
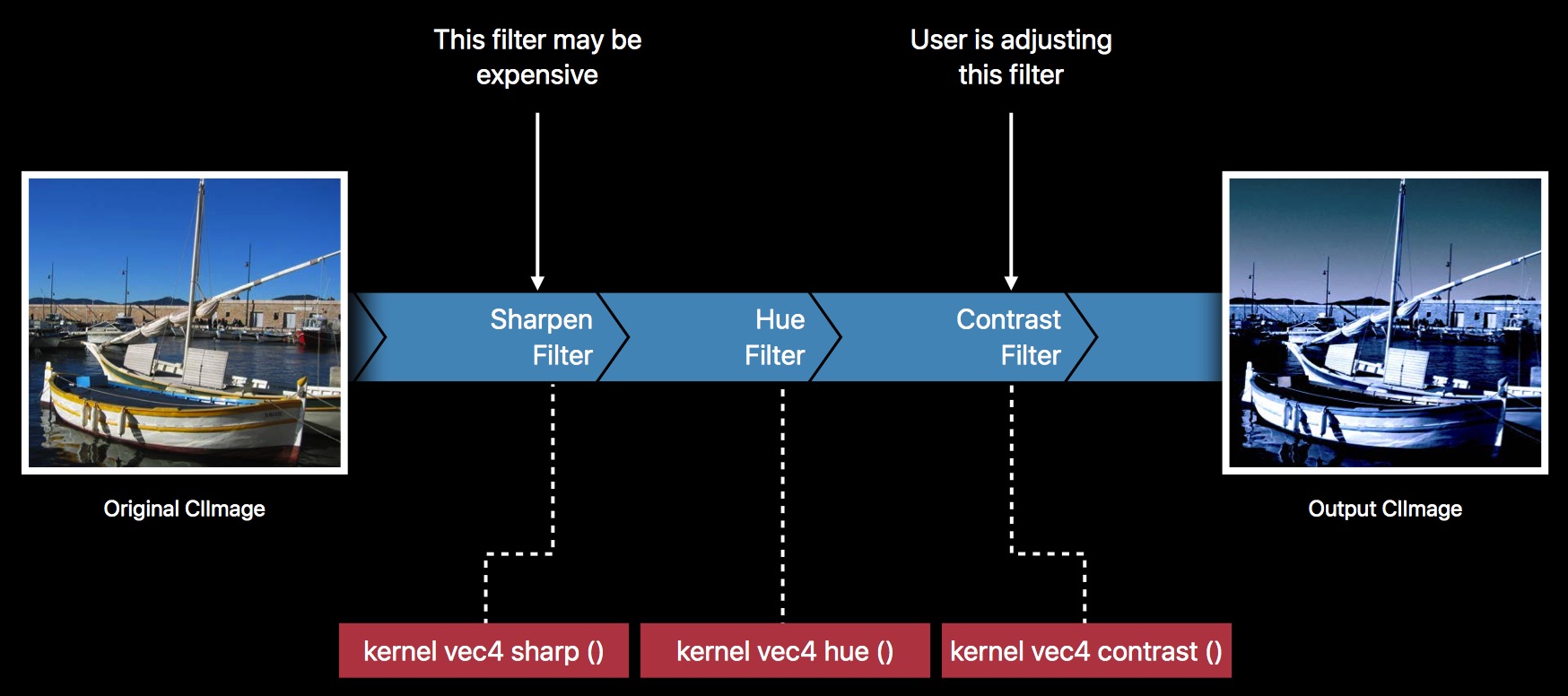
滤镜链里面的三个滤镜,Sharpen,Hue,Contrast。
其中,Sharpen 操作是比较耗时的,并且,用户能动态修改的,只有 Contrast。
所以如果按照常规的做法,每次修改 Contrast 程度值的时候,都重新跑一遍滤镜链,毫无疑问,会造成不必要的性能损耗。因为 Sharpen + Hue 这两个效果,任何情况下,出来的结果图都是一样的(因为没改变这两个 Filter 的程度值),并且它们本身也是比较耗时的。
当然,在介绍 Core Image 新功能之前,我们之前遇到类似的问题,是怎么解决的呢?
很明显,要引入一个临时的 CIImage,接收 Sharpen + Hue 处理出来的 outputImage。然后作为 inputImage,输入给 Contrast Filter。接下去的操作,都只处理 Contrast,它的 inputImage 暂存,固定不变。也就是将原有的一个滤镜链,拆分成两个。
当然,这种做法是可行的,也是目前的通用方式。只是在代码逻辑维护上,需要额外的成本。
那么,Core Image 会如何优化这个问题呢?
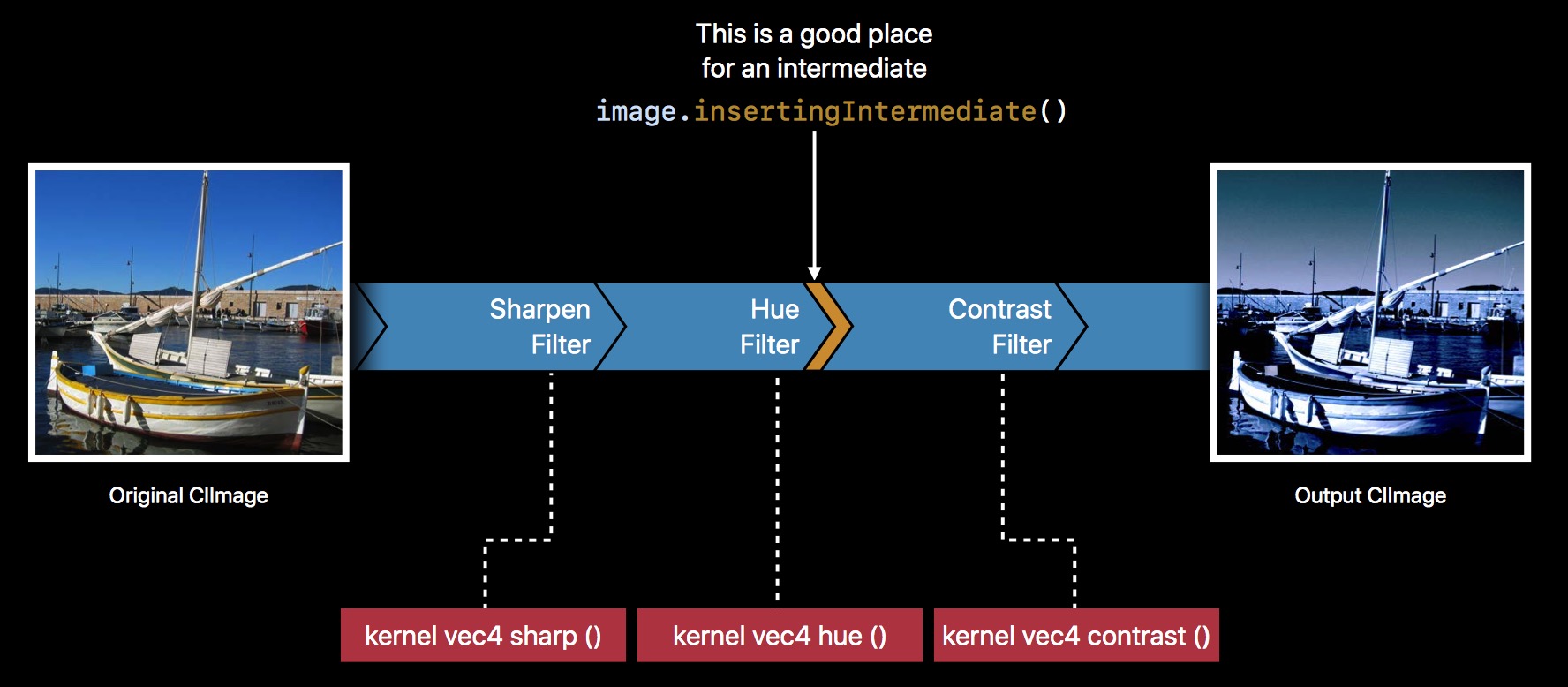
它的做法,其实和我们之前提到的一样,iOS 12 之后,CIImage 新增了一个方法,insertingIntermediate。
func insertingIntermediate() -> CIImage
// Returns a new image created by inserting an intermediate.
Hue 得到的 outputImage,调用 insertingIntermediate() 方法,再作为 inputImage 传入 Contrast,优化后的流程如下:
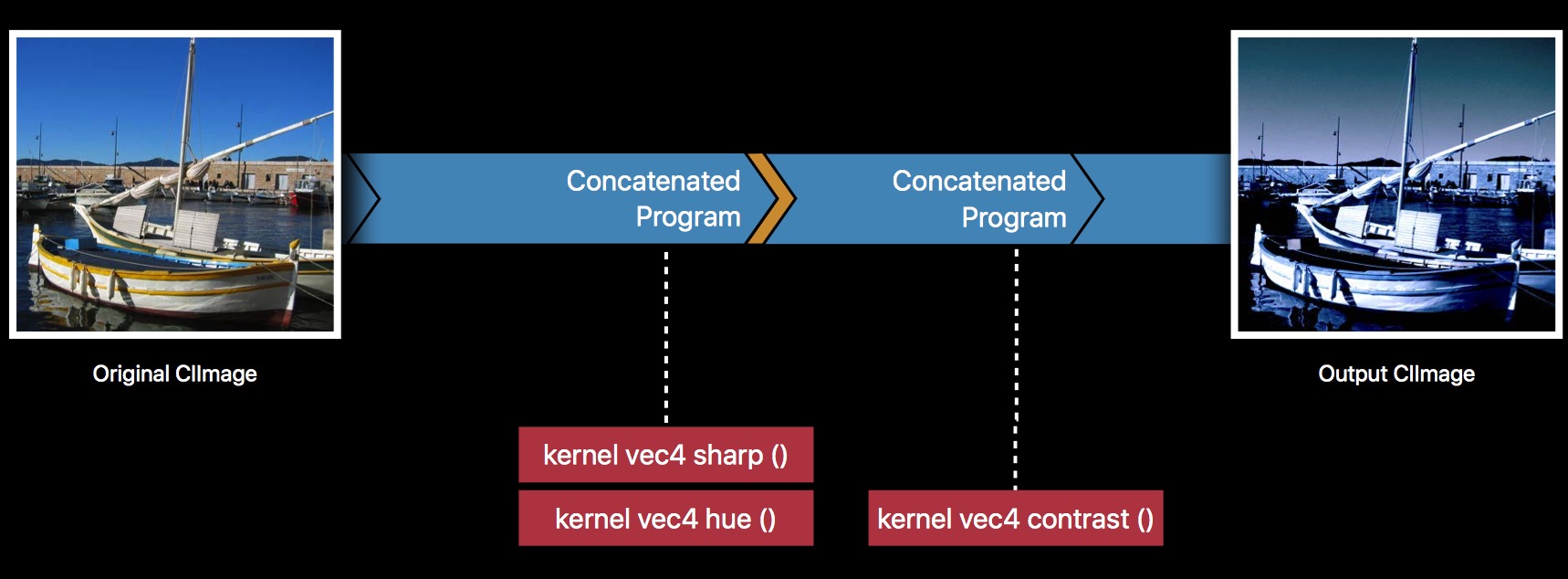
自动组合的逻辑,会根据 insertingIntermediate 做调整。这里,前两个 Filter 自动组合了。
对比我们自己维护多个滤镜链和系统提供的 insertingIntermediate,效率上应该是没什么差异,只是系统的使用起来更加方便罢了。
另外,使用上还要注意什么时候需要缓存,什么时候不需要缓存。Core Image 给我们提供了相关的属性,方便我们控制。
static let cacheIntermediates: CIContextOption
// The value for this key is an NSNumber object containing a Boolean value. If this value is false, the context empties such buffers during and after renders. The default value is true.
func insertingIntermediate(cache: Bool) -> CIImage
// Intermediate buffers created through setting cache to true have a higher priority than others. This setting is independent of of CIContext's cacheIntermediates option.
默认是缓存所有的 Intermediates,如果不需要,可以强制关闭。
let context = CIContext(options: [.cacheIntermediates: false] );
当然,CIContext 整体设置不缓存后,也可以针对个别 Intermediates 单独开启,下面的优先级更高
image.insertingIntermediate(cache: true);
总之,决定权在你自己。
new CIKernel Language features
在 2017 新特性中,我们提到过,CIKernel 支持 Metal 直接编写。所以目前自定义 Filter 有这么两种方式:
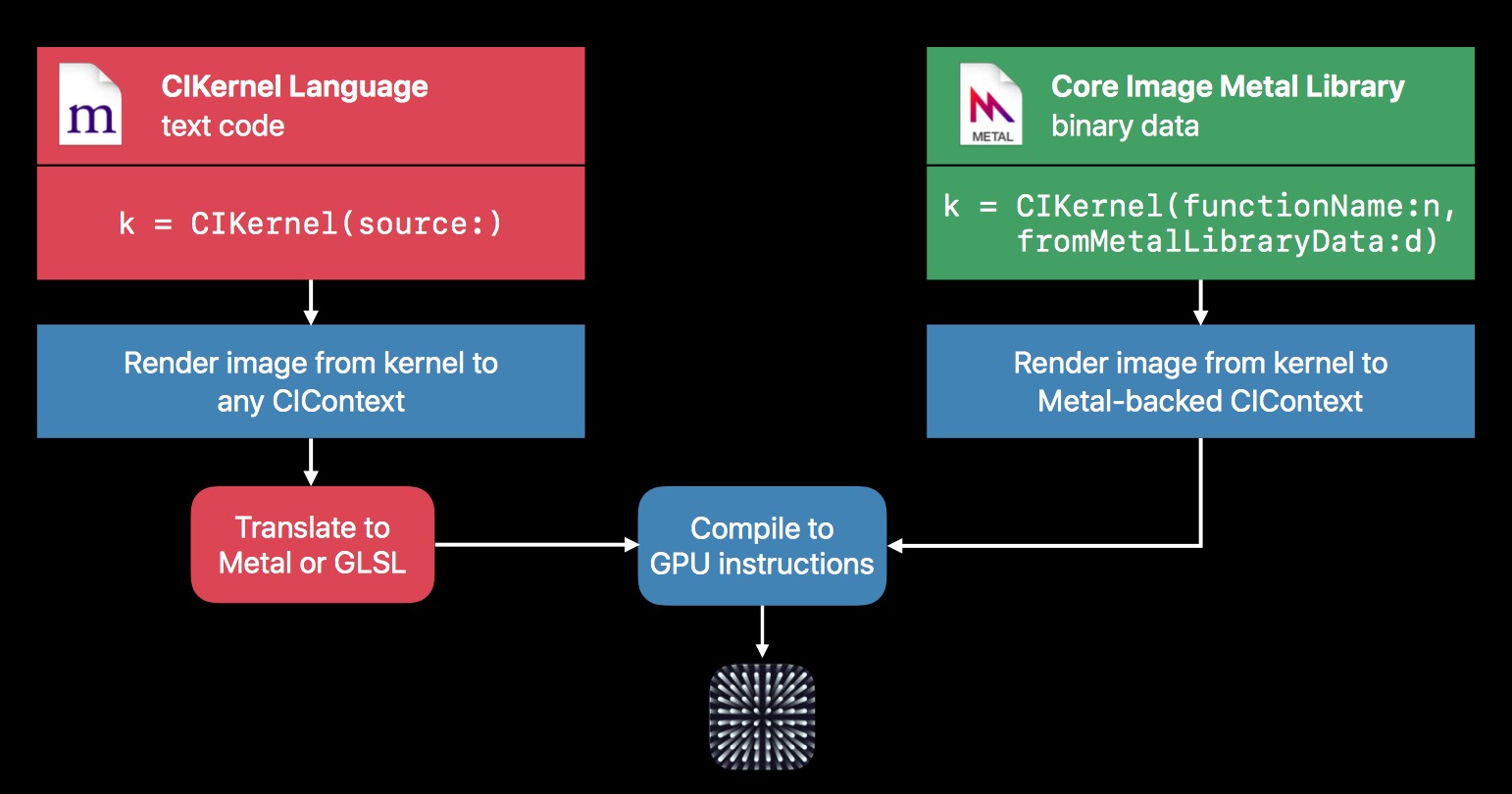
PS:
这两种之前的文章中都已经详细阐述了,这里不再说明,有疑惑的可以翻看之前的。
但是 iOS 12 之后,主推 Metal,不仅 OpenGL ES 被弃用,这里的 CIKernel Language 编写方式,也被弃用。当然,Metal 的性能优势还是很明显的,所以尽可能的使用 Metal,也是合理的。
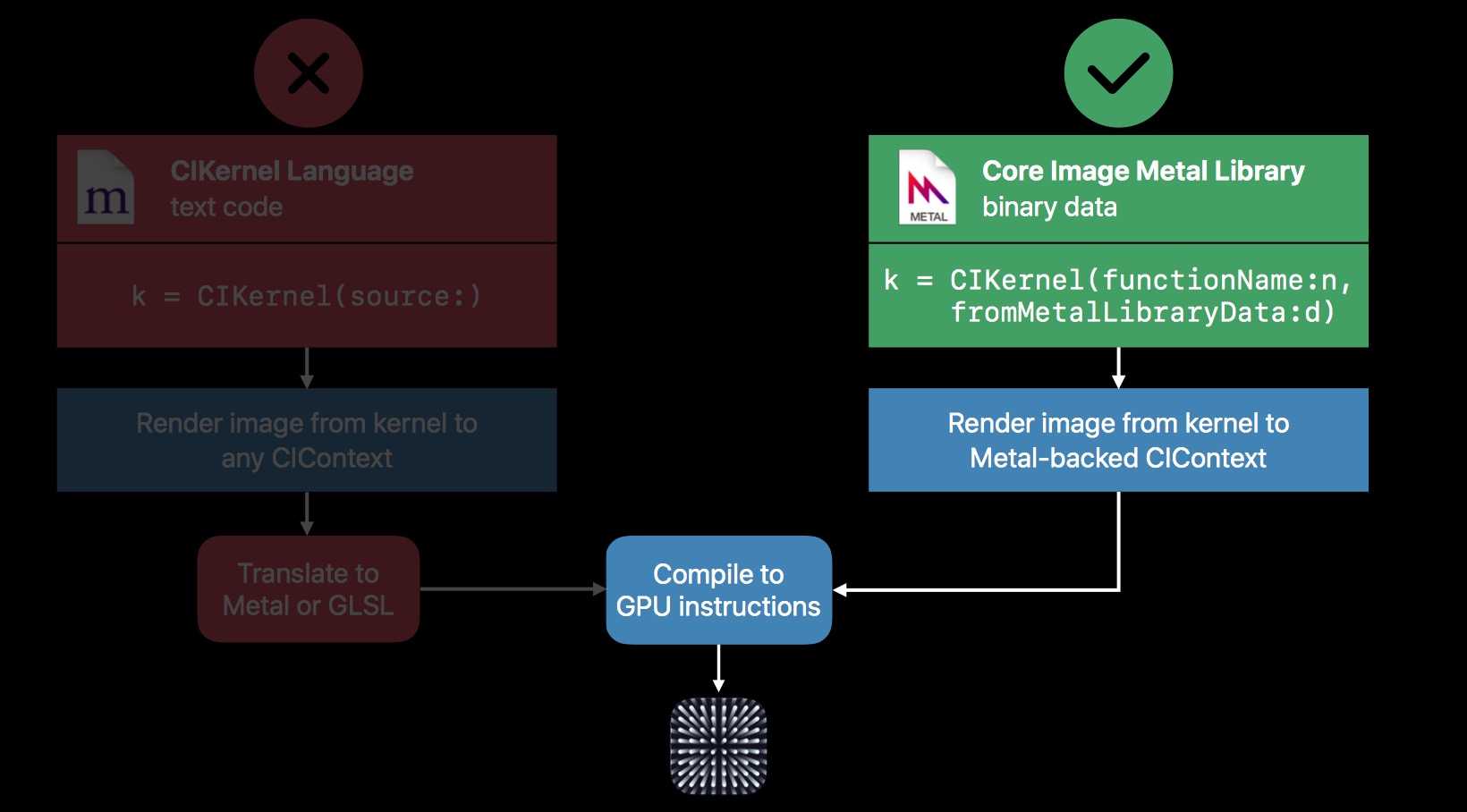
另外,CIKernel 还有两点比较重要的性能优化:
- Half float support
- Group reads
Half float support,支持半精度浮点数。
很多时候,half float 精度处理出来的效果,是足够好的,比如处理 RGB 的时候。
通过降低精度,使得运行速度变得更快,尤其是在 A11 芯片上。
另外,half float 的另一个优点是它可以使用更小的寄存器,从而能更充分的利用 GPU,进而提升效率。
接下去,重点分析下按组读写。
给 shader 提供了新的接口,实现单通道每次读取 4 个像素点,已经每次写入 4 个目标像素值。
这里举了一个卷积操作为例说明。
PS:
在图像处理中,卷积操作指的是使用一个卷积核对图像中的每个像素进行一系列操作。
卷积核(算子)是用来做图像处理时的矩阵,图像处理时也称为掩膜,是与原图像做运算的参数。
卷积核通常是一个四方形的网格结构(例如3x3的矩阵或像素区域),该区域上每个方格都有一个权重值。
使用卷积进行计算时,需要将卷积核的中心放置在要计算的像素上,一次计算核中每个元素和其覆盖的图像像素值的乘积并求和,得到的结构就是该位置的新像素值。
这里不细说,感兴趣的可以了解下 Convolutional Neural Networks。
如下图所示,展示了一个 3x3 的卷积核在 5x5 的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。
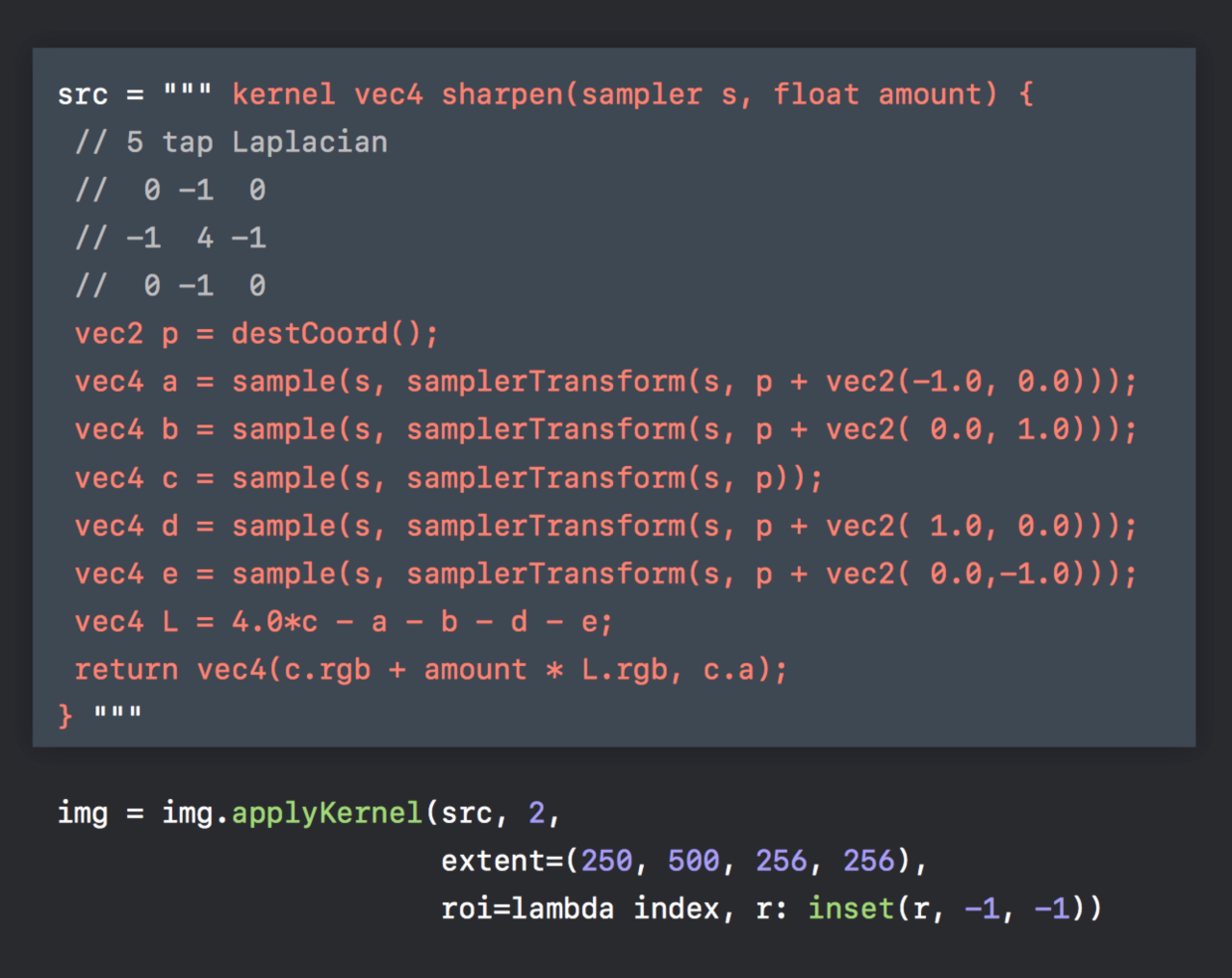
卷积在图像处理中最常见的应用为锐化和边缘提取。 感兴趣可以查阅下 kGPUImageSharpenFragmentShaderString,锐化算法就是根据周围区域像素值,计算得到中心区域最终像素值。

想象一下,我们有一个 3x3 的单通道卷积运算。按照上图的描述,我们每计算一次目标位置的像素值,就需要 9 次读操作,和 1 次写操作,如下:

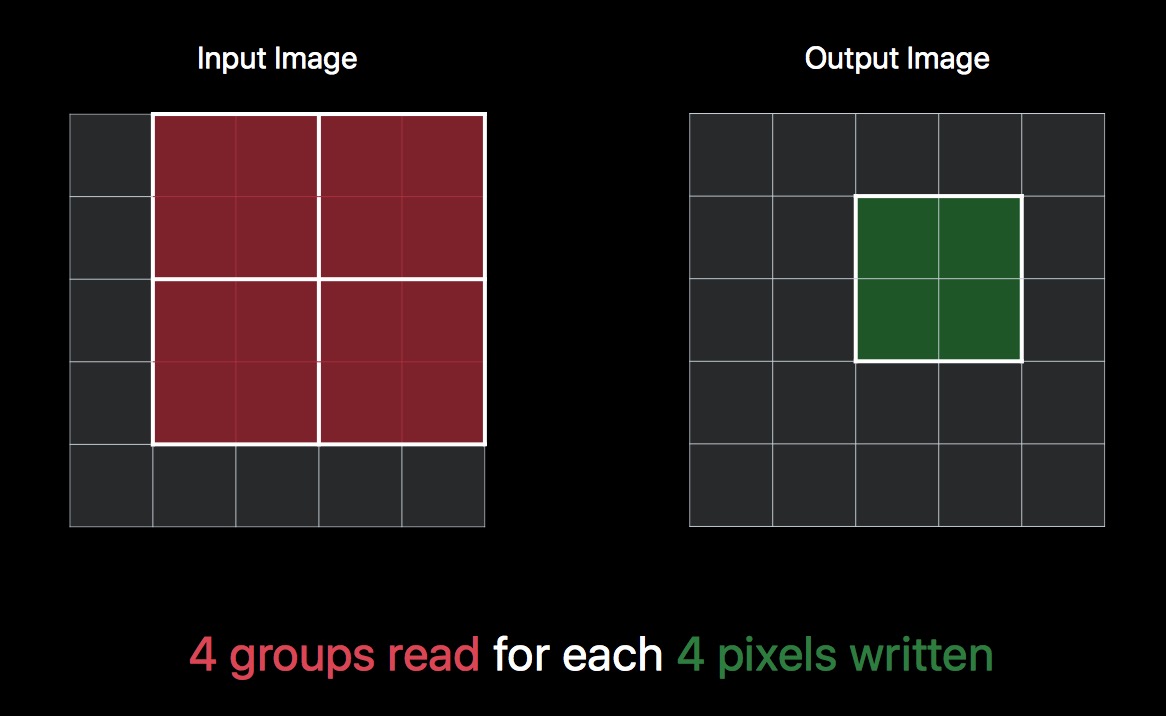
再复杂点,如果需要获取 4 个位置的像素值,按照之前逐个读写的方式,那么就需要 36 次的读操作,和 4 次的写操作。但是仔细观察最终读的区域,其实是有很大一部分重复的。如果能一次写入 4 个像素值,那么实际上只有 16 个位置的像素值需要读取。
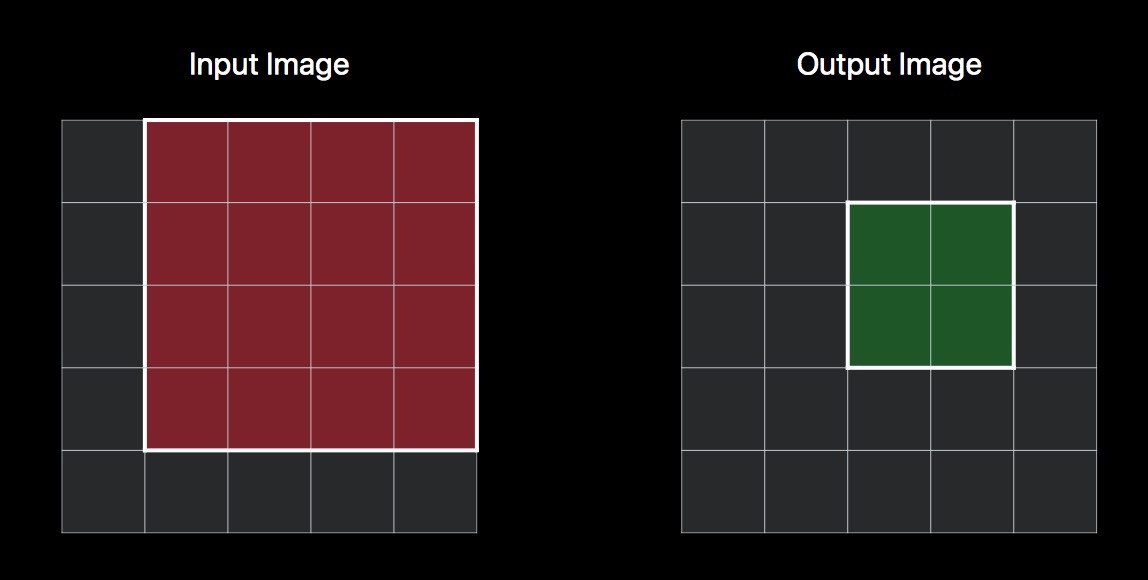
而 CIkernel 的一个新特性就是,支持按组写,优化这部分性能,所以上述操作,可以同时进行 16 次读操作,4 次写操作。
再进一步,CIKernel 还支持按组读,所以 16 次读操作,可以细分成 4 组来完成。最终,一次操作会完成:4 组 读,4 次写。
具体实践起来,kernel 代码如下:(这里是 r 通道的处理)
先把 float 换成 half,这是之前提到的一个优化点,如下是常规的读 9 次,写 1次。

按组读写优化后,代码如下:
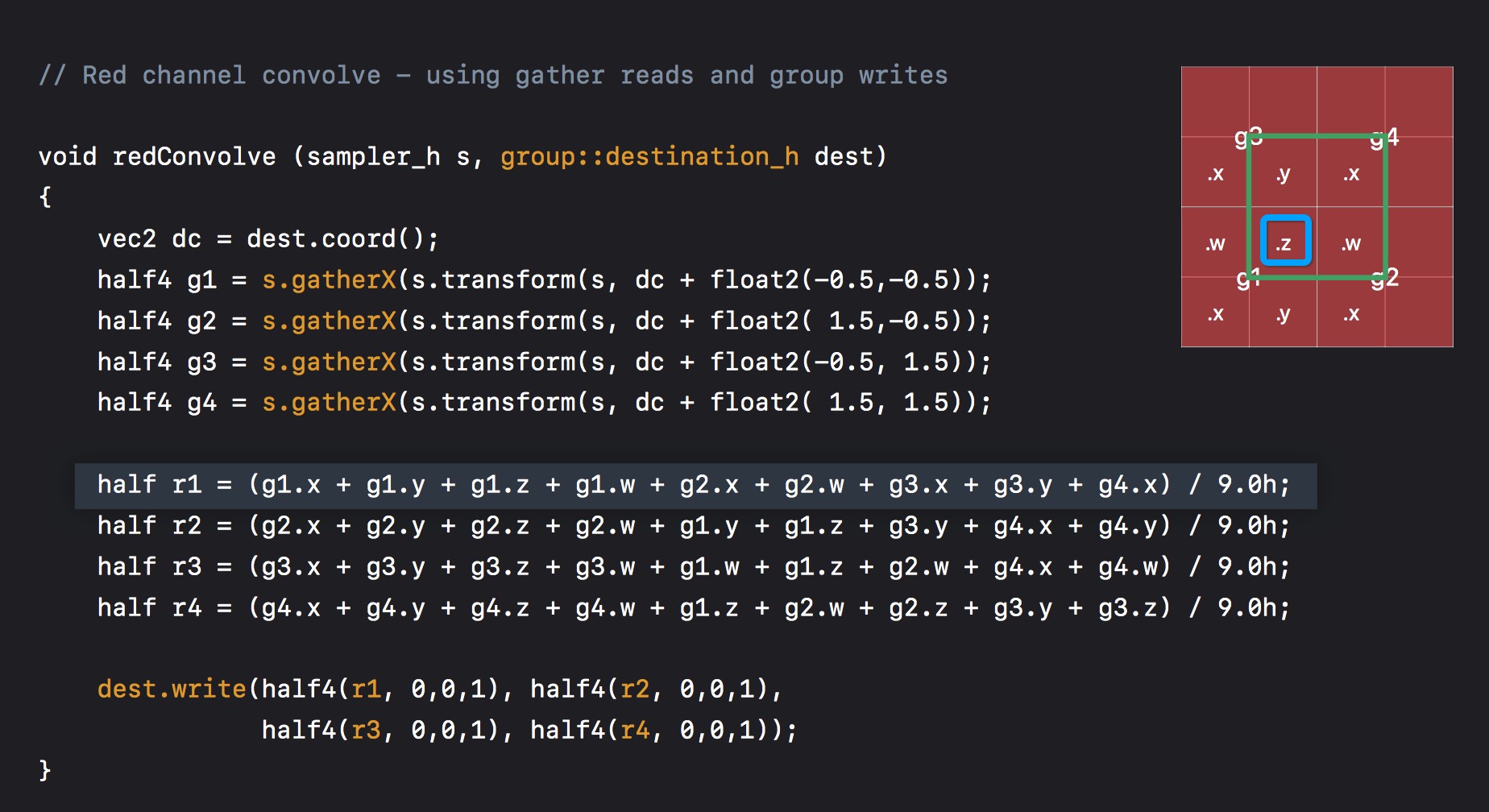
这里说明下。
如果需要按照写,那么需要对 dest 添加 group 修饰符。group::destination_h dest
蓝色区域,是当前处理的位置,即 dest.coord()。每个格子代表一个像素点。
dc + float2(-0.5, -0.5) 即 g1 的中心。同理可得 g1,g2,g3,g4。这里通过 s.gatherX 来实现分组。
然后 r1,即蓝色区域 r 通道值,则是通过周围 9 个像素点计算出来的,即
half r1 = (g1.x + g1.y + g1.z + g1.w + g2.x + g2.w + g3.x + g3.y + g4.x) / 9.0h;
同理可得,r1,r2,r3,r4。
最后,按照写入即可。
dest.write(half4(r1, 0,0,1), half4(r2, 0,0,1), half4(r3, 0,0,1), half4(r4, 0,0,1));
在这个简单的例子里,可以得到 2倍的性能提升。
所以其他类似的操作,尤其是卷积运算上,按组读写是一个提高性能的好办法。
Prototyping
回顾我们平时实现自研效果的流程:
特效同学,在电脑上模拟出最终的效果,然后我们(客户端开发)依照算法规则,在 iOS 平台上实现。
在这个过程中,经常会因为平台差异,或者工具差异,导致最终的效果不一致。比如颜色空间,技术可行性等等。
比如,我们想得到一个 人形区域 mask,可以通过 NumPy,OpenCV,TensorFlow,Python 等进行原型开发。但是在 iOS 平台上具体实现的时候,可以使用的只有 Core Image,Metal,MPS 等完全不同的东西。
这就可能出现因为工具的不完全一致,导致效果错误。

还有一个问题,就是性能。
在进行原型开发的时候,平台和工具不同,对内存和CPU/GPU 占用等,都没有具体的参考价值,这导致很多性能问题,会在最终实际开发过程中,才暴露出来。
为了解决上述提到的问题,Apple 引入了 PyCoreImage。
Python bindings for Core Image.
把 Core Image 强大的图像处理能力,和 Python 语言的灵活结合起来。

使用 PyCoreImage,可以最大程度的模拟真实环境,并且无需额外的学习成本。如果习惯用 Swift 的话,可以直接在 Playground 中模拟效果。
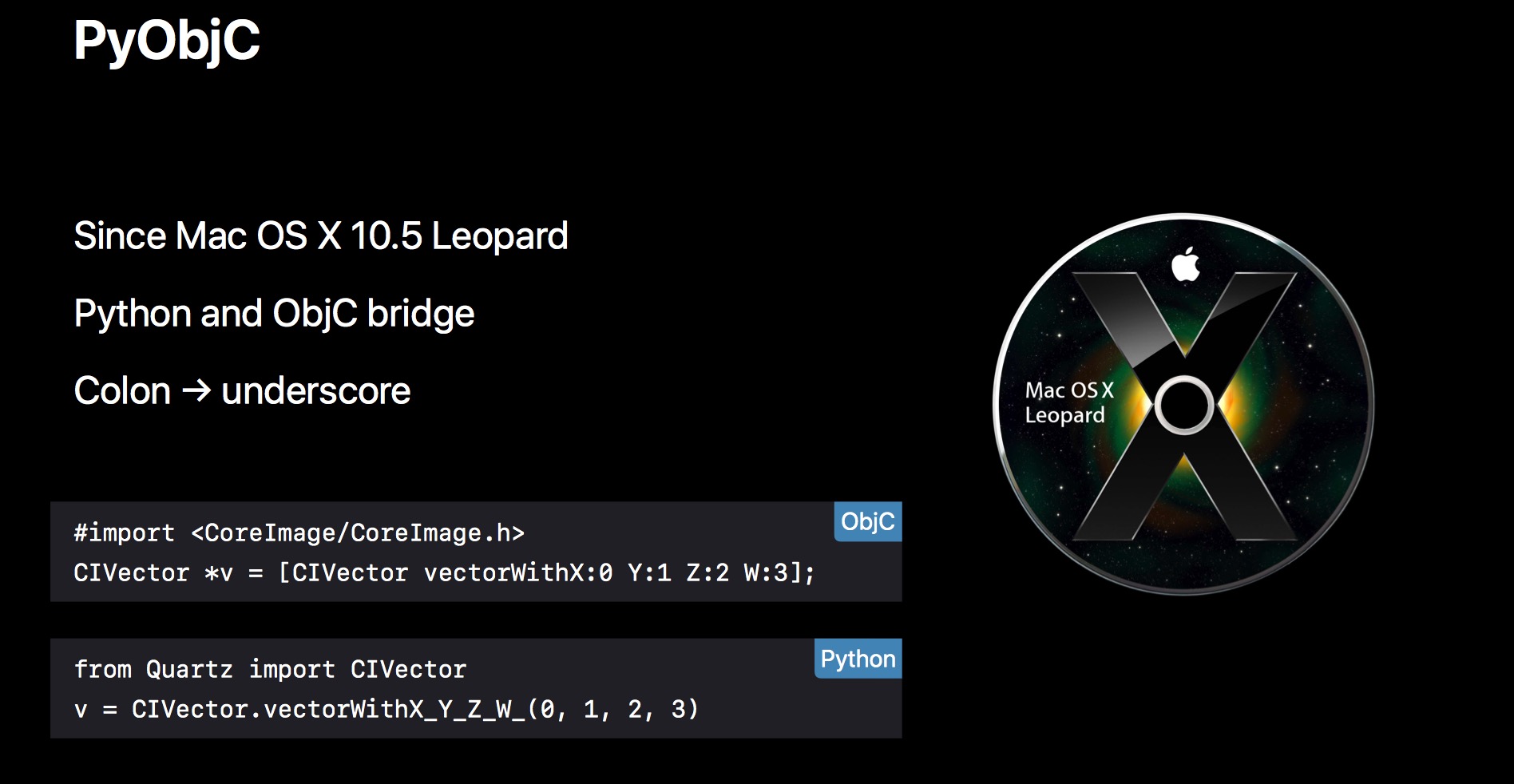
要使用 PyCoreImage,需要借助 Mac OS X 10.5 就引入的 PyObjC,它实现了在 Python 中调用 Objective-C 代码。
下面是一个简单的转换示例:
// Objc
#import <CoreImage/CoreImage.h>
CIVector *v = [CIVector vectorWithX:0 Y:1 Z:2 W:3];
// Python
from Quartz import CIVector
v = CIVector.vectorWithX_Y_Z_W_(0, 1, 2, 3)
至于 PyCoreImage 的整体架构,如下:
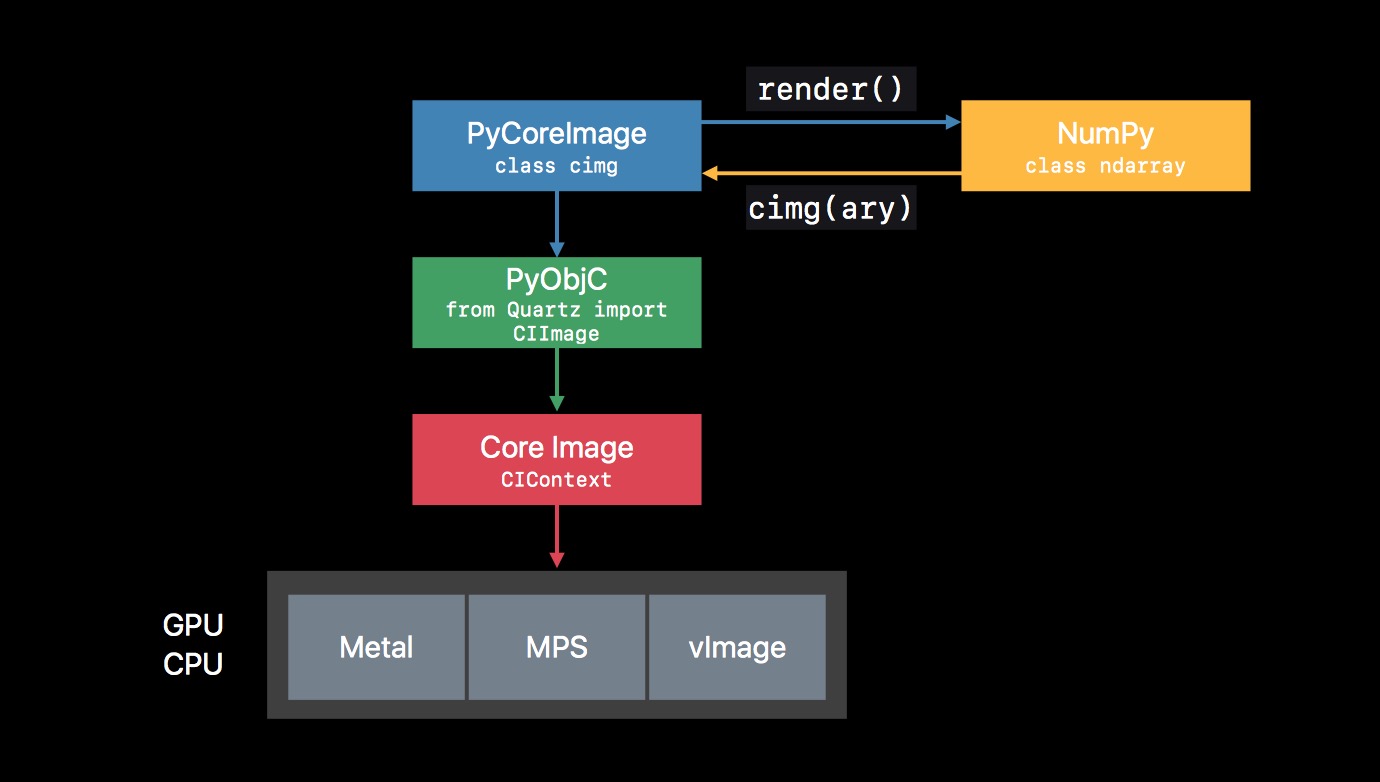
可以通过 NumPy 加载图片,获取二维图像数据数组,转为 CIImage 传入 PyCoreImage 中使用,PyCoreImage 通过 PyObjC,与 Core Image 进行交互,下发指令进行处理。
PS:
NumPy 是一个为 Python 提供高性能向量、矩阵和高维数据结构的科学计算库。它通过 C 和 Fortran 实现,因此用向量和矩阵建立方程并实现数值计算有非常好的性能。NumPy 基本上是所有使用 Python 进行数值计算的框架和包的基础,例如 TensorFlow 和 PyTorch,构建机器学习模型最基础的内容就是学会使用 NumPy 搭建计算过程。
NumPy 主要的运算对象为同质的多维数组,即由同一类型元素(一般是数字)组成的表格,且所有元素通过正整数元组进行索引。
下面是一个高斯模糊的具体例子:
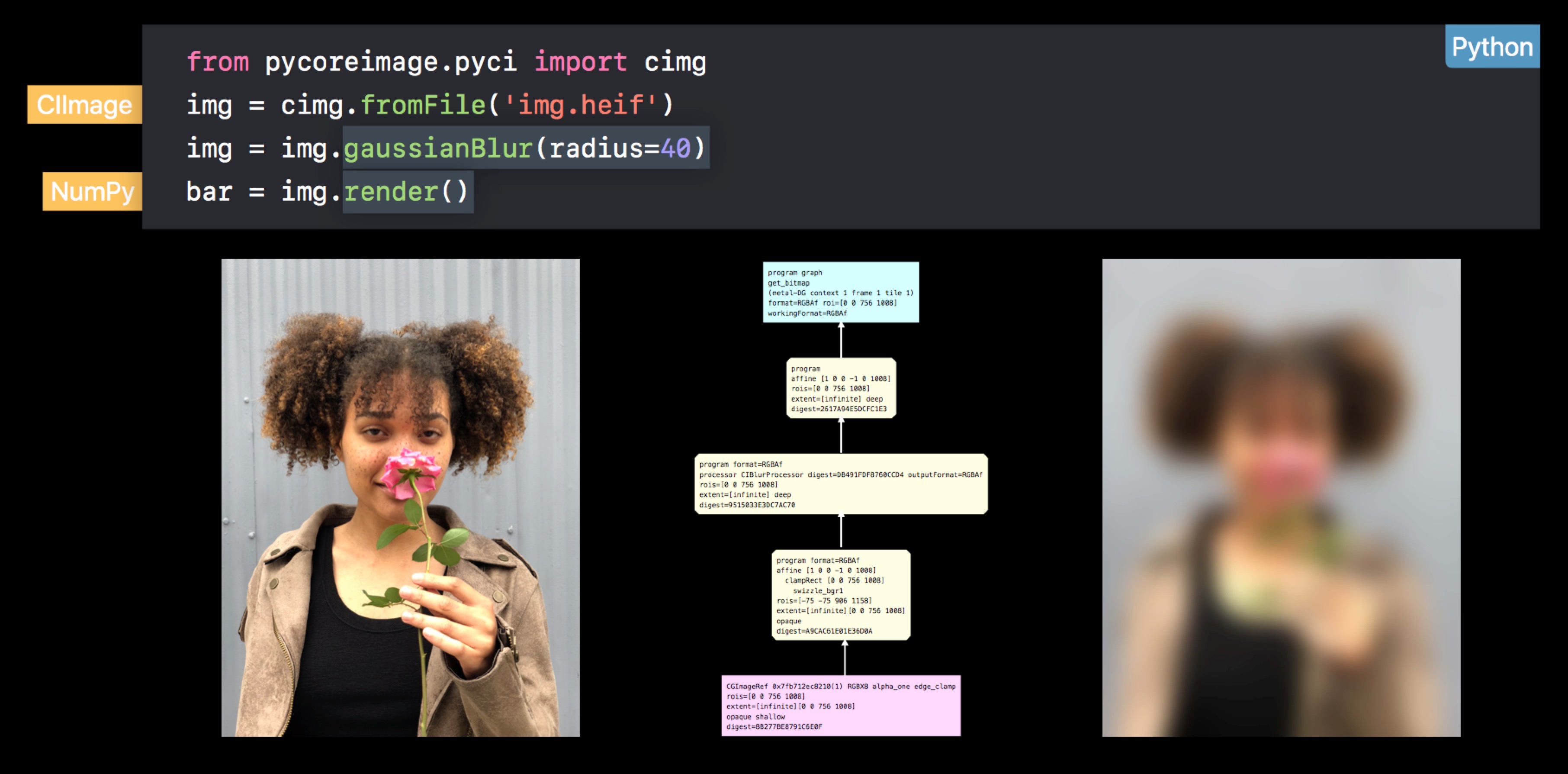
代码很简单,这里不具体说明。
另外,为了降低学习成本,PyCoreImage 对比 Core Image 做了一些简化,比如颜色空间统一为 sRGB 等。绿色标注即差异项:

下面是一个备忘录,列举了常用的一些操作:
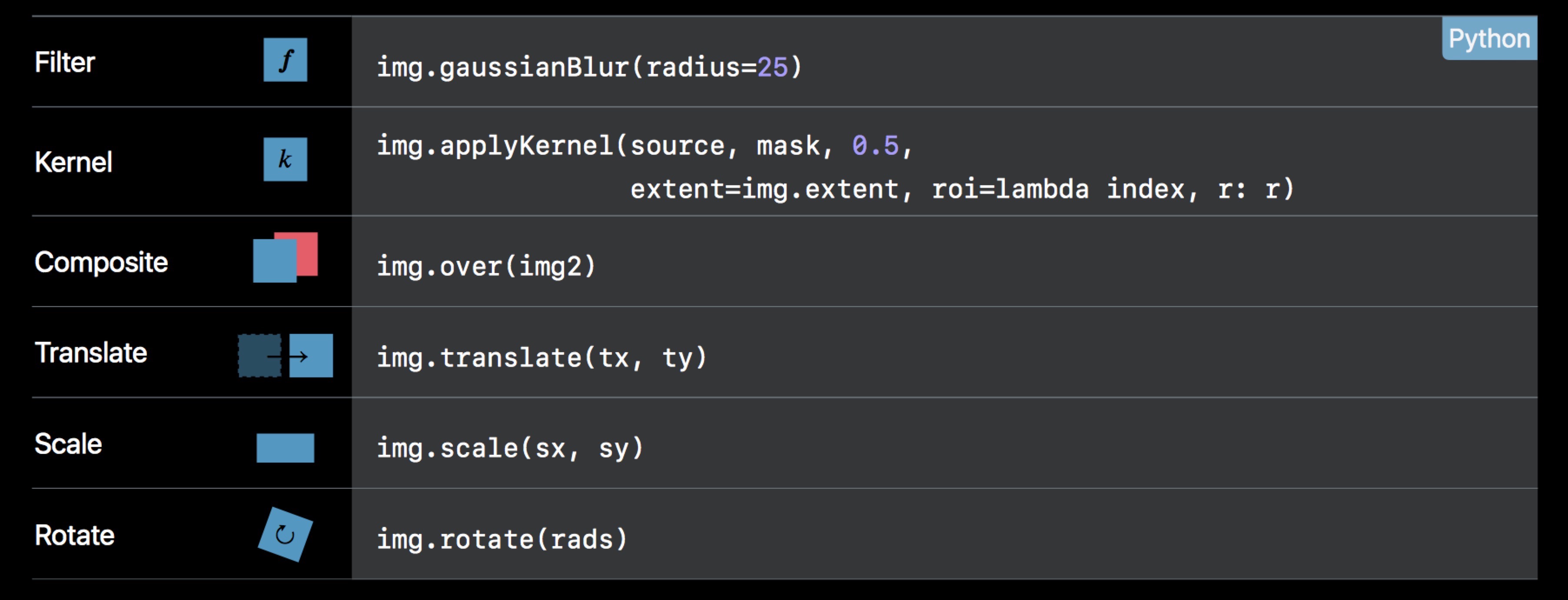
这里额外提一个,Kernel 的加载方式。
自定义 Filter,可以通过如下方式加载并应用效果。这里可以留意到,kernel 和我们在 iOS 上用的完全一致,真正的减少了移植的成本。
如果想了解这部分的更多知识,包括安装方式,其他 API 等,可以查阅官方文档:
Prototyping Your App’s Core Image Pipeline with Python
Machine Learning
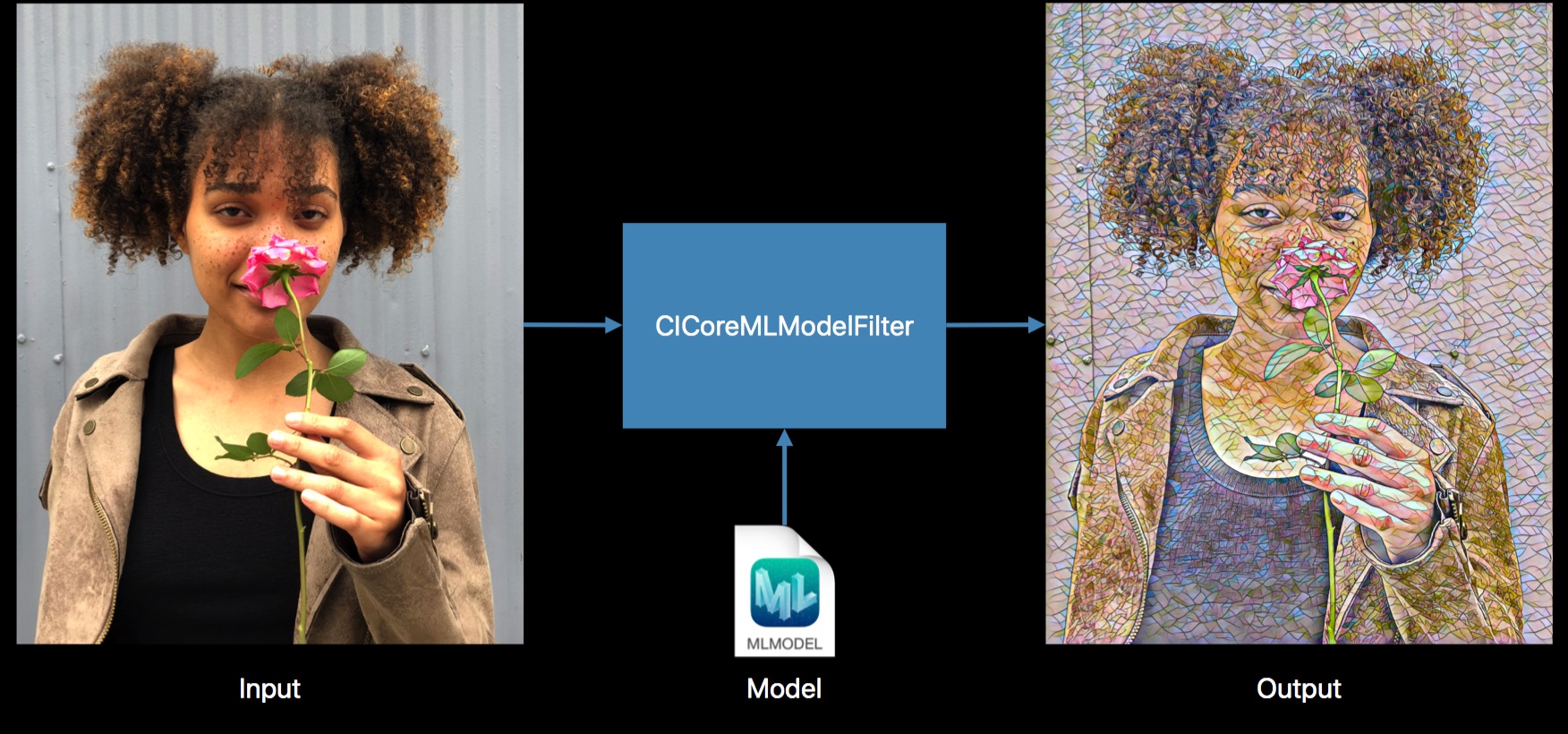
新加入了一个内置 Filter,CICoreMLModelFilter,可以和方便的与 CoreML 结合起来,实现效果。
参数十分简洁,就两个,inputImage 和 inputModel。如下:
let result = image.applyingFilter("CICoreMLModelFilter", parameters: ["inputModel": model])!
PS:
不过目前在官方文档上,还搜不到 CICoreMLModelFilter 的任何内容,内置的 CIFilter 也找不到,估计还没开放。
关于与 CoreML 的配合,这里还提了一点。
当我们在训练模型的时候,其实就是我们调参的过程,这样模型能将具体的输入(比如说图像)映射为输出(标签)。我们的优化目标就是尽力让模型的损失调低,当然需要往正确的方向调整模型参数才行。成功的神经网络拥有数以百万计的参数!自然而然,如果你有很多参数,就需要为模型展示大量的样本,才能让模型获得良好的性能。
所以说,训练集和模型的准确性成正比。不同类型的大量数据,对神经网络的鲁棒性起着至关重要的作用。
但不得不提到,真实数据的采集是十分困难的。这种情况下,我们一般会借助 Data Augmentation 来模拟,填充数据。
PS:
在深度学习中,有的时候训练集不够多,或者某一类数据较少,或者为了防止过拟合,让模型更加鲁棒性, Data Augmentation 是一个不错的选择。
普通的图像增强方法包括:翻转、旋转、平移、裁剪、缩放和高斯噪声;高级版图像增强方法还有常数填充、反射、边缘延伸、对称和包裹模式等。
借助 Core Image 内置滤镜,可以十分方便实现图像增强。
如下是几个具体例子:

另外,结合 PyCoreImage,在电脑上可以快速生成样本数据。如下是具体的实践代码:
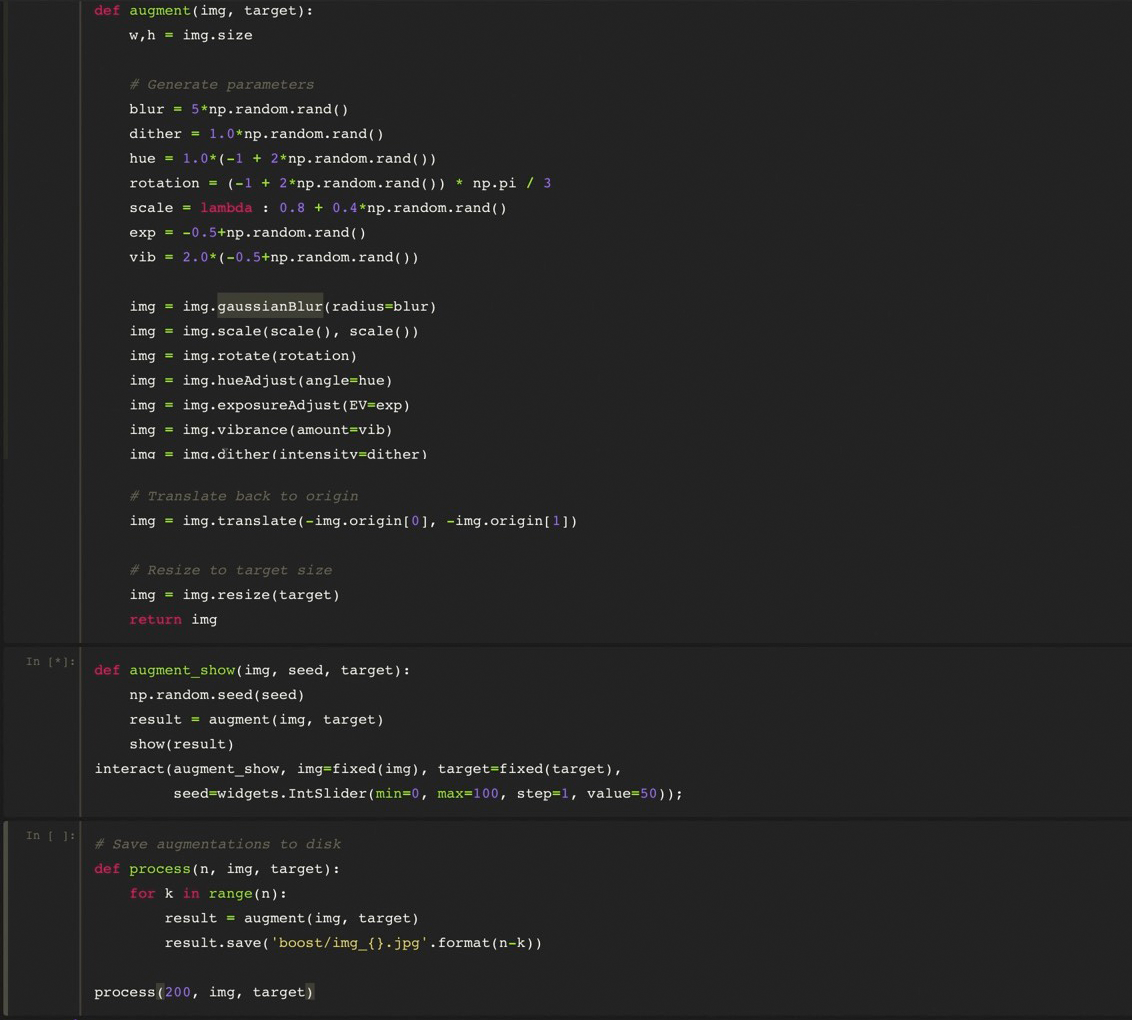
运行后,就可以得到大量样本啦~